
分享一篇hanlp分词工具使用的小案例,即利用hanlp分词工具分析两个中文语句的相似度的案例。供大家一起学习参考!
在做考试系统需求时,后台题库系统提供录入题目的功能。在录入题目的时候,由于题目来源广泛,且参与录入题目的人有多位,因此容易出现录入重复题目的情况。所以需要实现语句相似度分析功能,从而筛选出重复的题目并人工处理之。
下面介绍如何使用Java实现上述想法,完成语句相似度分析:
1、使用HanLP完成分词:
首先,添加HanLP的依赖:(jsoup是为了处理题干中的html标签,去除html标签得到纯文本的题干内容)
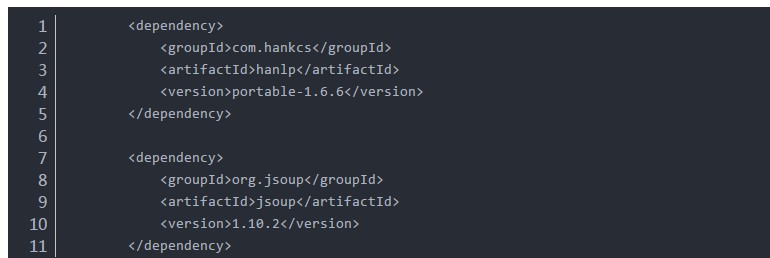
分词代码如下,需要处理html标签和标点符号:
private static List<String> getSplitWords(String sentence) {
// 去除掉html标签
sentence = Jsoup.parse(sentence.replace(" ","")).body().text();
// 标点符号会被单独分为一个Term,去除之
return HanLP.segment(sentence).stream().map(a -> a.word).filter(s -> !"`~!@#$^&*()=|{}':;',\\[\\].<>/?~!@#¥……&*()——|{}【】‘;:”“'。,、? ".contains(s)).collect(Collectors.toList());
}
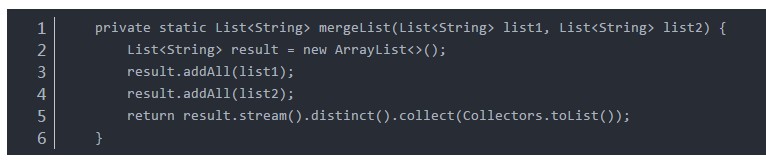
2、合并分词结果,列出所有的词:
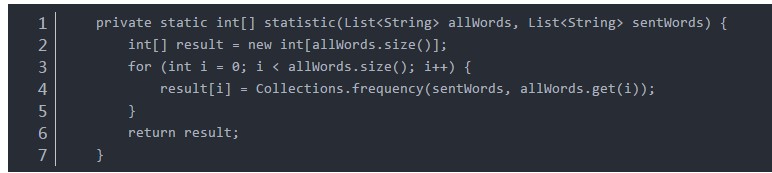
3、统计词频,得到词频构成的向量:
代码如下,其中allWords是上一步中得到的所有的词,sentWords是第一步中对单个句子的分词结果:
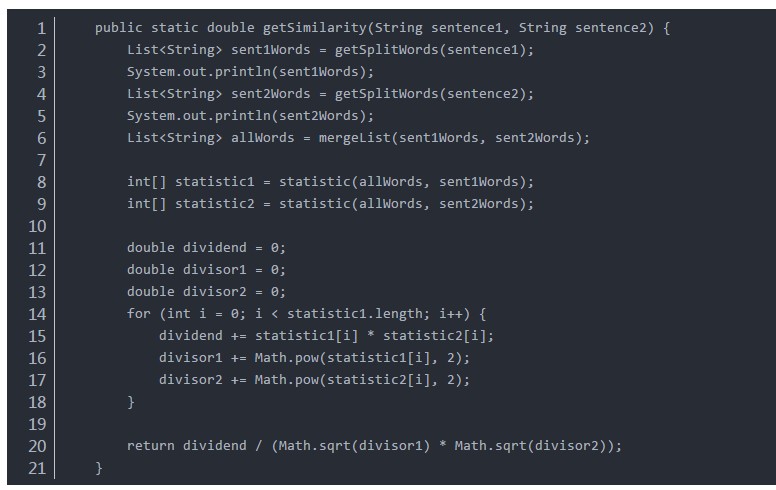
4、计算相似度(两个向量的余弦值):
以上所有方法的完整代码如下,使用SimilarityUtil.getSimilarity(String s1,String s2)即可得到s1和s2的语句相似度:
package com.yuantu.dubbo.provider.questionRepo.utils;
import com.hankcs.hanlp.HanLP;
import com.hankcs.hanlp.dictionary.CustomDictionary;
import org.jsoup.Jsoup;
import java.util.ArrayList;
import java.util.Calendar;
import java.util.Collections;
import java.util.List;
import java.util.stream.Collectors;
public class SimilarityUtil {
static {
CustomDictionary.add("子类");
CustomDictionary.add("父类");
}
private SimilarityUtil() {
}
/**
* 获得两个句子的相似度
*
* sentence1
* sentence2
*
*/
public static double getSimilarity(String sentence1, String sentence2) {
List<String> sent1Words = getSplitWords(sentence1);
System.out.println(sent1Words);
List<String> sent2Words = getSplitWords(sentence2);
System.out.println(sent2Words);
List<String> allWords = mergeList(sent1Words, sent2Words);
int[] statistic1 = statistic(allWords, sent1Words);
int[] statistic2 = statistic(allWords, sent2Words);
double dividend = 0;
double divisor1 = 0;
double divisor2 = 0;
for (int i = 0; i < statistic1.length; i++) {
dividend += statistic1[i] * statistic2[i];
divisor1 += Math.pow(statistic1[i], 2);
divisor2 += Math.pow(statistic2[i], 2);
}
return dividend / (Math.sqrt(divisor1) * Math.sqrt(divisor2));
}
private static int[] statistic(List<String> allWords, List<String> sentWords) {
int[] result = new int[allWords.size()];
for (int i = 0; i < allWords.size(); i++) {
result[i] = Collections.frequency(sentWords, allWords.get(i));
}
return result;
}
private static List<String> mergeList(List<String> list1, List<String> list2) {
List<String> result = new ArrayList<>();
result.addAll(list1);
result.addAll(list2);
return result.stream().distinct().collect(Collectors.toList());
}
private static List<String> getSplitWords(String sentence) {
// 去除掉html标签
sentence = Jsoup.parse(sentence.replace(" ","")).body().text();
// 标点符号会被单独分为一个Term,去除之
return HanLP.segment(sentence).stream().map(a -> a.word).filter(s -> !"`~!@#$^&*()=|{}':;',\\[\\].<>/?~!@#¥……&*()——|{}【】‘;:”“'。,、? ".contains(s)).collect(Collectors.toList());
}
}
---------------------